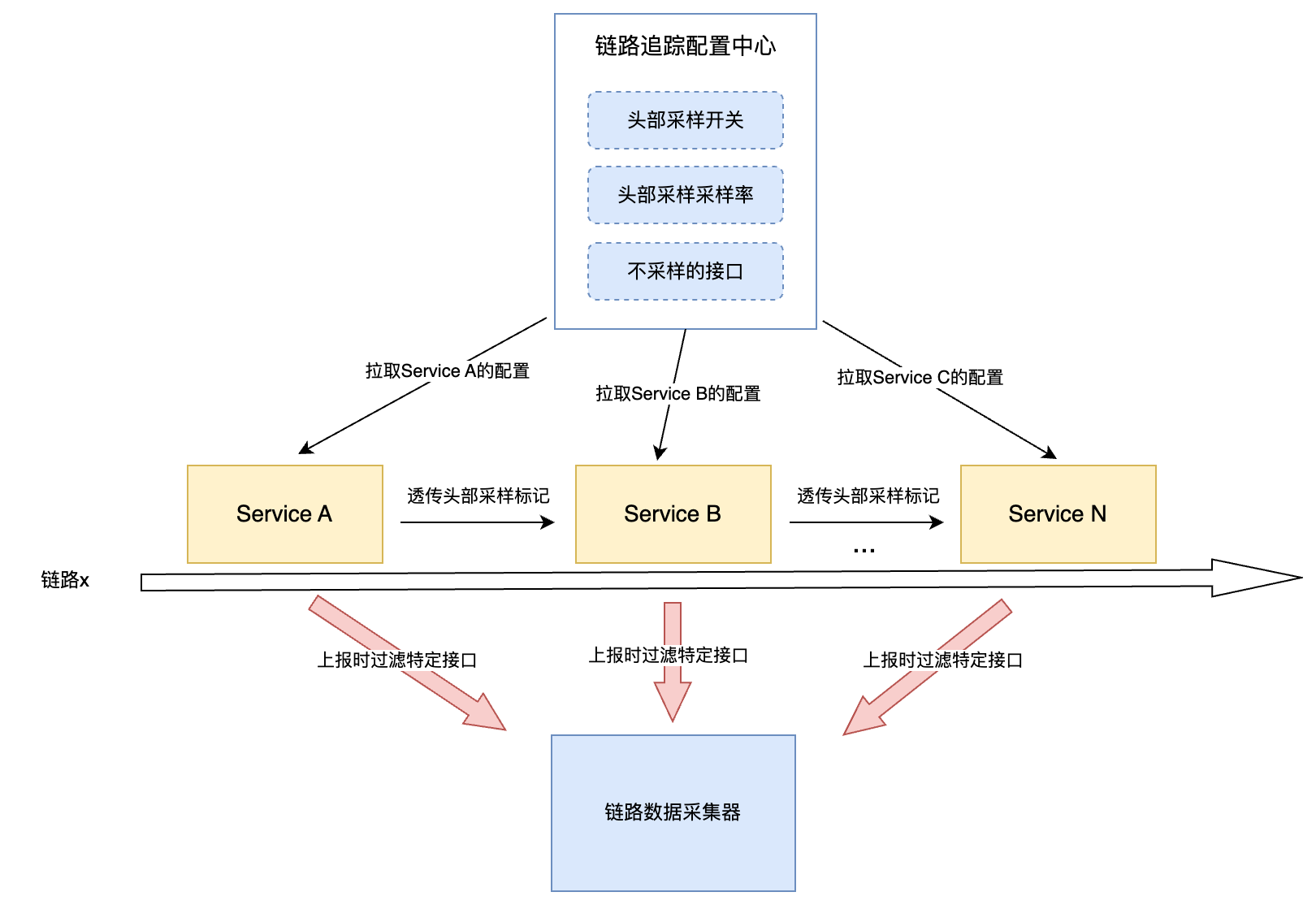
链路追踪数据量大,如果全采样不仅对于客户端的IO负担很大,而且对于采集侧的内存、IO压力巨大,因此需要采样策略来决定哪些链路数据需要采样,哪些不需要。本篇文章介绍了一些常见的链路追踪采样策略及其在业界的实现方式。
概率采样 概率采样是指只采集某一个概率/比例的链路数据,保证只有一部分的数据被采样,减少数据量。常见的做法是使用trace id计算概率。
使用trace id计算hash值,之后用该hash值作为生成随机数的seed,并与设定的采样概率做比较决定是否采样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class SamplingEvaluator { private static final Random random = new Random (); public static boolean shouldSample (double sampleRate) { return random.nextFloat() < sampleRate; } public static boolean shouldSample (String traceId, double sampleRate) { if (StringUtils.isBlank(traceId)) { return false ; } long hash = HashUtil.fnv64a(traceId); float sampleValue = HashUtil.nextFloat(hash); return sampleValue < sampleRate; } }
opentelemetry对于概率采样的实现,opentelemetry的trace id中包含随机数,可以直接使用该随机数进行概率判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @Immutable final class TraceIdRatioBasedSampler implements Sampler { static TraceIdRatioBasedSampler create (double ratio) { if (ratio < 0.0 || ratio > 1.0 ) { throw new IllegalArgumentException ("ratio must be in range [0.0, 1.0]" ); } long idUpperBound; if (ratio == 0.0 ) { idUpperBound = Long.MIN_VALUE; } else if (ratio == 1.0 ) { idUpperBound = Long.MAX_VALUE; } else { idUpperBound = (long ) (ratio * Long.MAX_VALUE); } return new TraceIdRatioBasedSampler (ratio, idUpperBound); } @Override public SamplingResult shouldSample ( Context parentContext, String traceId, String name, SpanKind spanKind, Attributes attributes, List<LinkData> parentLinks) { return Math.abs(getTraceIdRandomPart(traceId)) < idUpperBound ? POSITIVE_SAMPLING_RESULT : NEGATIVE_SAMPLING_RESULT; } }
头部采样 头部采样是指在一条链路的开始决定该条链路是否要被采样,如果需要被采样则在上下文(context)中透传采样标记,表示全链路采样。OpenTelemetry Sdk实现了头部采样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @Immutable final class ParentBasedSampler implements Sampler { @Override public SamplingResult shouldSample ( Context parentContext, String traceId, String name, SpanKind spanKind, Attributes attributes, List<LinkData> parentLinks) { SpanContext parentSpanContext = Span.fromContext(parentContext).getSpanContext(); if (!parentSpanContext.isValid()) { return this .root.shouldSample( parentContext, traceId, name, spanKind, attributes, parentLinks); } if (parentSpanContext.isRemote()) { return parentSpanContext.isSampled() ? this .remoteParentSampled.shouldSample( parentContext, traceId, name, spanKind, attributes, parentLinks) : this .remoteParentNotSampled.shouldSample( parentContext, traceId, name, spanKind, attributes, parentLinks); } return parentSpanContext.isSampled() ? this .localParentSampled.shouldSample( parentContext, traceId, name, spanKind, attributes, parentLinks) : this .localParentNotSampled.shouldSample( parentContext, traceId, name, spanKind, attributes, parentLinks); } }
头部概率采样 头部采样加上概率是指在头部服务计算概率是否命中,如果命中则之后的链路数据全采样,否则不采样。如果采样命中,则其会在链路调用发生跨进程/线程数据透传的时候,在上下文信息中带上采样标记,表示该链路数据需要被采样。
1 2 3 4 5 6 7 8 9 10 11 if (traceConfig != null && traceConfig.isEntrySampledOpen()) { Double entrySampledRate = traceConfig.getEntrySampledRate(); if (entrySampledRate != null ) { if (entrySampledRate >= 1.0 ) { dtc.addSamplingStrategy(SamplingStrategy.HEAD_ENTRY); } else if (entrySampledRate > 0 && SamplingEvaluator.shouldSample(traceContext.getTraceId(), entrySampledRate)) { dtc.addSamplingStrategy(SamplingStrategy.HEAD_ENTRY); } } }
入口固定数量采样 每一条链路都有一个入口,该入口可能是一个Http Url,可能是一个服务接口,那么为了保证在一段时间内每一个入口都有一定数量的链路数据被采样到,我们设置了入口固定数量采样策略,使用计数器存储一个时间窗口内某一个入口的链路采样数量。其同样通过头部采样标记透传标识链路需要被采样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (traceConfig != null && traceConfig.isEntrySampledOpen()) { if ((traceContext.getSamplingStrategy() & SamplingStrategy.HEAD_ENTRY.getValue()) == 0 ) { boolean headHit = false ; int keyCapacity = traceConfig.getEntrySampledKeyCountPerSec(); int valueCapacity = traceConfig.getEntrySampledValueCountPerSec(); if (StringUtils.isNotEmpty(headHttpUrl)) { headHit = HeadEntryFilter.getInstance().hit(headHttpUrl, keyCapacity, valueCapacity); } else if (StringUtils.isNotEmpty(headRpcService)) { headHit = HeadEntryFilter.getInstance().hit(headRpcService, keyCapacity, valueCapacity); } if (headHit) { dtc.addSamplingStrategy(SamplingStrategy.HEAD_ENTRY); } } }
固定数量采样 Skywalking对Span进行计数,决定是否采样。sample_n_per_3_secs配置,每3秒的限制数量,计数器计数进行比较:
对于带有上游报文数据的entry span必定采样
对于local span、exit span和无上游报文数据的entry span部分采样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @DefaultImplementor public class SamplingService implements BootService { public boolean trySampling (String operationName) { if (on) { int factor = samplingFactorHolder.get(); if (factor < samplingRateWatcher.getSamplingRate()) { return samplingFactorHolder.compareAndSet(factor, factor + 1 ); } else { return false ; } } return true ; } }
根据系统容量采样 Skywalking中有根据系统CPU利用率判断是否采样的采样器
1 2 3 4 5 6 7 8 9 10 11 12 13 @OverrideImplementor(SamplingService.class) public class TraceSamplerCpuPolicyExtendService extends SamplingService { @Override public boolean trySampling (final String operationName) { if (cpuUsagePercentLimitOn) { double cpuUsagePercent = jvmService.getCpuUsagePercent(); if (cpuUsagePercent > TraceSamplerCpuPolicyPluginConfig.Plugin.CpuPolicy.SAMPLE_CPU_USAGE_PERCENT_LIMIT) { return false ; } } return super .trySampling(operationName); } }
标签采样 可以为Span打上标签,在采样时与配置中需要采样的标签进行匹配,如果匹配上了则采样。
1 2 3 4 5 6 7 8 9 10 11 12 private void addSamplingFlagIfNeed (String key, String value) { TraceConfig config = m_manager.getConfigManager().getTraceConfig(); TraceContext traceContext = m_manager.getThreadLocalTraceContext(); if (config != null && traceContext instanceof DefaultTraceContext){ List<Pair<Pattern, Pattern>> patternList = config.getTagSampledSelectors(); if (tagMatched(patternList, key, value)){ DefaultTraceContext defaultTraceContext = (DefaultTraceContext)traceContext; defaultTraceContext.addSamplingStrategy(SamplingStrategy.TAG_RULE); } } }
后置采样 对于链路中出现需要保留的链路,该节点之后的所有链路都会保留,常见于异常,慢请求,特定用户ID等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private static void putTraceContext (Context ctx, TraceContext traceContext) { if (!messageTree.canDiscard()) { if (config != null && config.isPostSampledOpen() && traceContext instanceof DefaultTraceContext) { DefaultTraceContext defaultTraceContext = (DefaultTraceContext) traceContext; defaultTraceContext.addSamplingStrategy(SamplingStrategy.POST); } } if (traceContext.getSamplingStrategy() > 0 ) { int sampleStrategy = traceContext.getSamplingStrategy(); sampleStrategy &= 0xfffffff7 ; ctx.addProperty(TraceContext.SAMPLED, String.valueOf(sampleStrategy)); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Override public void logError (String message, Throwable cause) { if (Cat.getManager().isCatEnabled()) { if (shouldLog(cause)) { StringWriter writer = new StringWriter (2048 ); if (message != null ) { writer.write(StringUtils.truncate(message, CatConstants.EXCEPT_LINER_LIMIT)); writer.write(' ' ); } if (ProblemFilter.hit(cause)) { m_manager.getThreadLocalMessageTree().setDiscard(false ); cause.printStackTrace(new ThrowablePrintWriter (writer)); } else { writer.write("stacktrace was throttled" ); } } } }
尾部采样 上面的采样策略都是在客户端决定是否采样,而尾部采样可以在采集侧采集到整条链路数据之后再决定是否需要存储这条链路。Opentelemetry Collector目前支持了该尾部采样策略 ,同时据我所知阿里云团队目前也支持了该种采样策略,其可以做到在采集侧暂时保存5min全量的链路数据。使用尾部采样策略我们可以对整条链路进行定制化的采集,比如我们可以采集整条链路耗时超过特定阈值的链路,可以采集有特殊状态码的整条链路。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 processors: tail_sampling: decision_wait: 10s num_traces: 100 expected_new_traces_per_sec: 100 policies: [ { name: policy-1 , type: status_code , status_code: {status_codes: [ERROR ]} }, { name: policy-2 , type: probabilistic , probabilistic: {sampling_percentage: 20 } } ]
decision_wait:在做出采样决定之前,从 trace 的第一个跨度开始的等待时间
num_traces:内存中保存的 trace 数
expected_new_traces_per_sec:预期的新 trace 数
policies:采样策略集合
Reference
Skywalking Java Agent代码仓库 Opentelemetry Java Sdk代码仓库 Opentelemetry-Collector代码仓库 OpenTelemetry Sampling 可观测性专题: 分布式追踪中的采样 StabilityGuide - 链路追踪(Tracing)其实很简单——链路成本进阶指南 OpenTelemetry 采样最佳实践