
Join Algorithms
1. Nested Loop Join
1.1 Simple / Stupid
1 | foreach tuple r 属于 R: |
1 | // M是外层表的page数,m是外层表的tuple数量;N是内层表的page数。 |
1.2 Block
每一次读取内层表中的每一个page作为一个block和外层表一起处理,此时相当于是让外层表和内层表的page进行join(而不是像上面的stupid方式一样按照tuple进行join),此时的IO cost如下所示:
1 | IO cost = M + M*N |
如果我们使用B-2个buffer来扫描外部表(另两个buffer用于扫描内部表,两个交替来减少io时间开销)
IO cost = M + ($ \lceil {M/(B-2)} \rceil $ * N )
1.3 Index
利用一些其它信息进一步降低开销,比如索引(这个索引可以是之前就建立好的,或者临时建立一个用于join操作)。
1 | // C是平均每次索引查询操作的复杂度 |
2. Sort-Merge Join
1 | // R是外层表,S是内层表 |
有可能会触发回溯操作,比如外部表有两个特定key相同的tuple,由于匹配后内部表指针会自增,第二个tuple匹配的情况会被忽略。所以当我移动外部表的游标,并且它匹配内部表刚看到的最后一个tuple,那么就对内部表进行回溯操作。
1 | Sort Cost(R): 2M * (logM / logB) |
最糟糕的情况是两个表中所有的tuple都相同。
如果两个表的聚簇索引的键正好是join操作需要的键,那么就不需要做排序操作了。
3. Hash Join
1 | build hash table HT_r for R: // build phase |
Hash table values
Approach #1: Full Tuple
Approach #2: Tuple Identifier
Probe phase optimization
创建一个bloom filter来预先检查一个key是否可能存在于hash table中。
bloom filter是一个hash table,其每一位对应的是一个key被多个hash function分别映射得到的结果。当查询一个key是否在一个hash table中时,如果该key被hash table映射的bit有一个不为1,则表示该key不存在于该hash table中;但是如果映射的每个bit都为1,则只能表示该key可能存在于该hash table中。
Grace Hash Join
Join each pair of matching buckets between table R and S。
理想情况是所有buckets都能放进内存里,但是当数据量太大时,bucket往往无法放进内存里,此时就要做拆分,当一个bucket的大小超过某个阈值的时候,可以使用recursive partitioning来对数据进行递归分区,如下图所示:
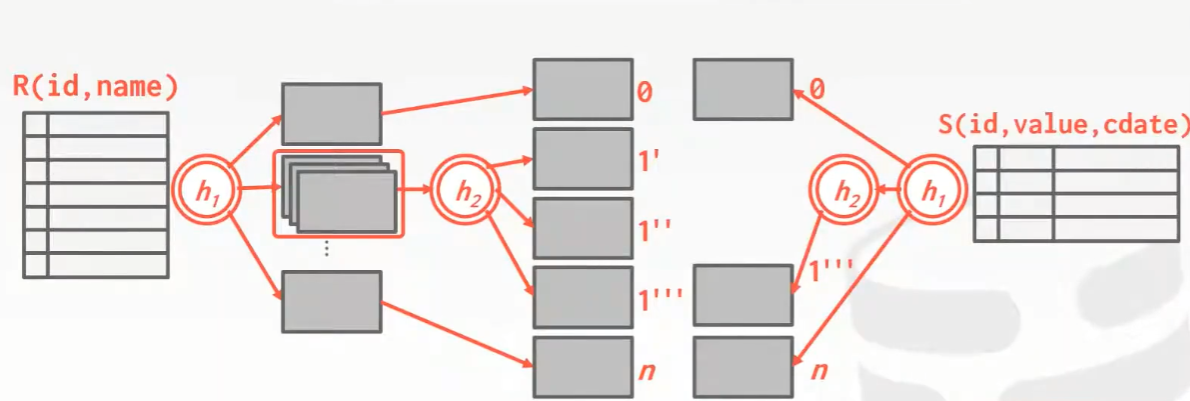
当所有数据都在一个bucket且难以拆分时,此时就只能使用最普通的nested loop join了。
1 | Cost of hash join: 3(M+N) |
- 本文标题:CMU15-445笔记9——Join Algorithms
- 本文作者:mufiye
- 创建时间:2022-08-29 20:54:17
- 本文链接:http://mufiye.github.io/2022/08/29/CMU15-445笔记9——Join-Algorithms/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!