
Hash Table
hash table或者b+树等数据结构在数据库中的作用:
- 内部元数据(meta internal data):page表或者page目录
- 核心数据存储(core data storage):此时数据结构的值就是tuple,memcache用的是page tabe,mysql的innodb引擎用的是b+树
- 临时数据(temporary data structures)
- 表索引(table indexs):是能够快速找到想要的元素
1. Hash Function
- how to map a large key space into a smaller domain.
- Trade-off between being fast vs. collision rate.
知名的hash函数:
- CRC-64
- MurmurHash
- Google CityHash
- Facebook XXHash(仍在不断改进,其最快)
- Google FarmHash
2. Hashing Scheme
- how to handle key collisions after hashing.
- Trade-off between allocating a large hash table vs. additional instructions to find/insert keys.
2.1 Static Hashing Schemes
Static Hashing Schemes是指提前知道我想要保存的key的大概数量。
1) Linear Probe Hashing
解决hash碰撞的方法是,如果我们进行hash计算所得到的slot位置上已经有数据在上面了,如果我试着往里面插入数据,我们会挨着这条数据往下扫描,直到我们遇到下一个能够插入的空slot为止,然后我们将我们试着添加的那个entry插到这个slot上。当我们做查找的时候,我会先找到hash函数所计算出的那个offset所在的地方,接着我会继续往下扫描,直到我找到一个空slot。(hash table的每个条目会存储hash key和hash value,正常是不需要放hash key的值的)
当对hash table中的数据进行删除时,有这么几种策略,一种是在删除数据的位置放一个墓碑标志(tombstone)表示该位置逻辑上无效;一种是移动数据,将下面的数据向上移动(这可能会导致错误)。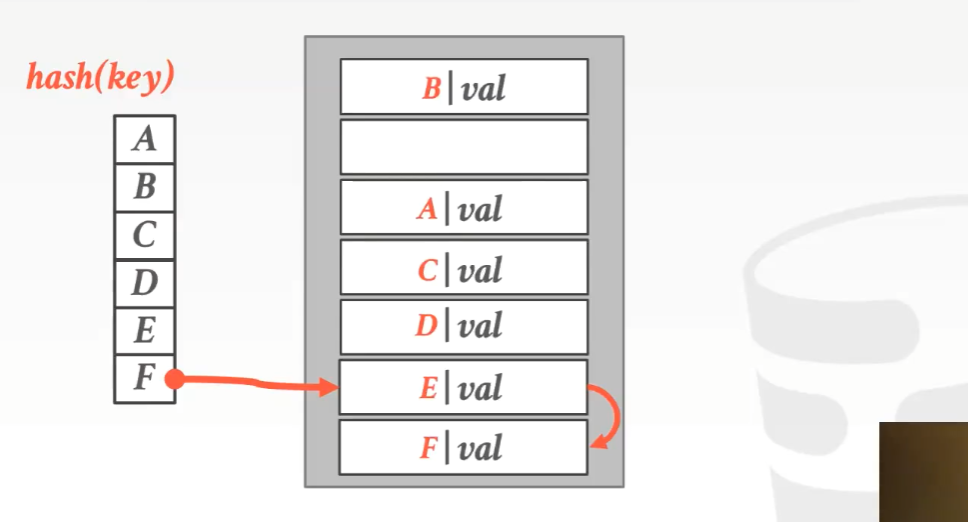
2) Robin Hood Hashing
罗宾汉,劫富济贫,平均财富。
poor key会从rich key偷取slot,poor或是rich由存储位置与第一次进行hash所计算出的位置间的距离差来决定。其根本思想就是试着对整个hash table进行平衡,试着让每个key尽可能地靠近它原本所在的位置。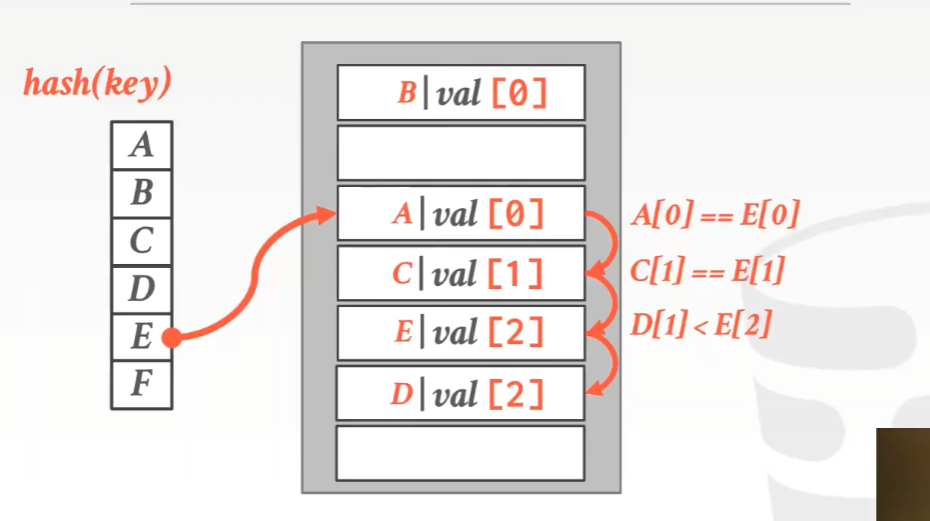
3) Cuckoo Hashing
使用两个hash table,这两个hash table可以使用相同的hash function但是它们的seed不相同,如果两个hash function得到的位置结果都是空的话,那么随机选择;如果得到的结果有一个为空,一个不为空,则填充到空的位置;如果两个都为非空,则随机选择一个位置进行抢占,被抢占的元素递归地再次进行之前的流程。这个方法也有无法完全解决碰撞的可能性,此时就要进行扩容操作(该操作会改变hash function中的相应数值)。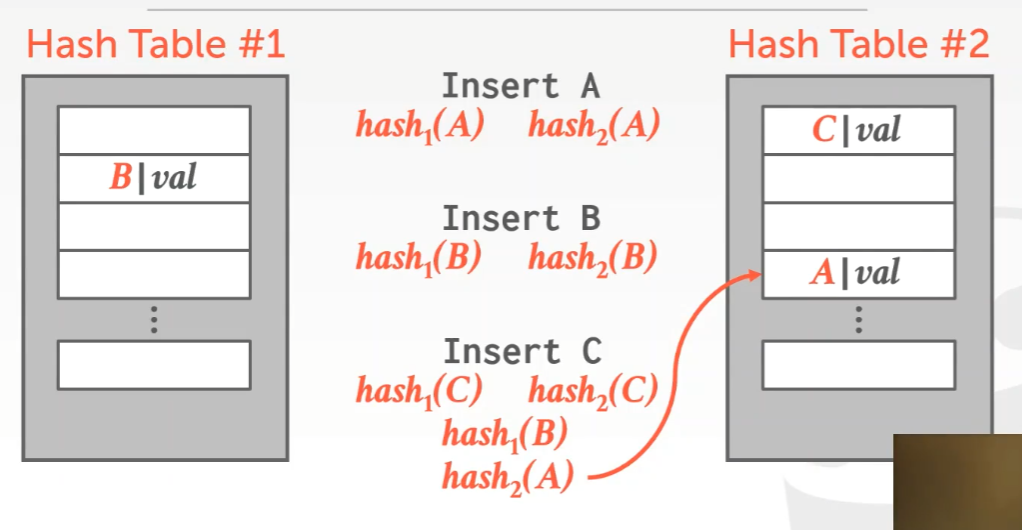
2.2 Dynamic Hashing Schemes
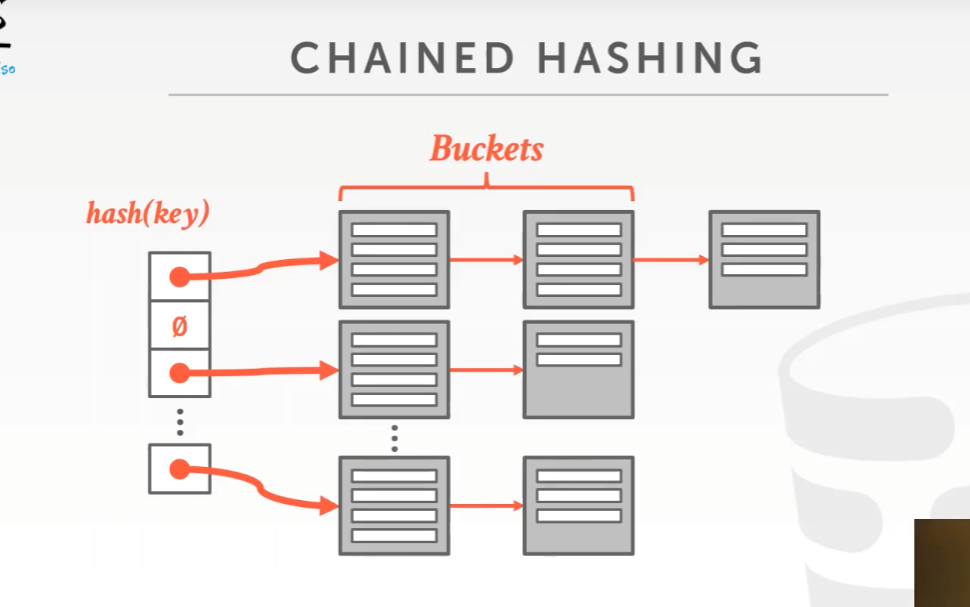
1) Chained Hashing
java中默认的hashmap实现,它会维护一个包含了buckets的链表,通过将相同hash key的所有元素放入相同的bucket解决冲突。做插入操作时,只是将slot array插入到bucket中,如果bucket满了的话就在末尾再添加一个bucket。这些bucket相当于是page,添加bucket相当于是分配新的page,DBMS通过page id来遍历它们。
2) Extendible Hashing
为了避免chained hashing这样没有限制的增长(这会导致最后的查询复杂度变为O(n)),我们选择对overflow的bucket做拆分。该方法的hash table基本结构和chained hashing很类似,不过有一些额外的信息,有一个global counter和每个bucket都有一个local counter,其中global counter表示需要考虑几个bit,local counter中记录的数字表示的意思是需要看几个bit才能找到该slot的位置。如果有某个bucket溢出了,那么就引入更多的bit来确定slot的位置(global counter和local counter都会变化),hash table包含的链表数量也会变化。(需要补充的是,这里的hash function的结果是一串二进制数字,因此每一位为一个bit。)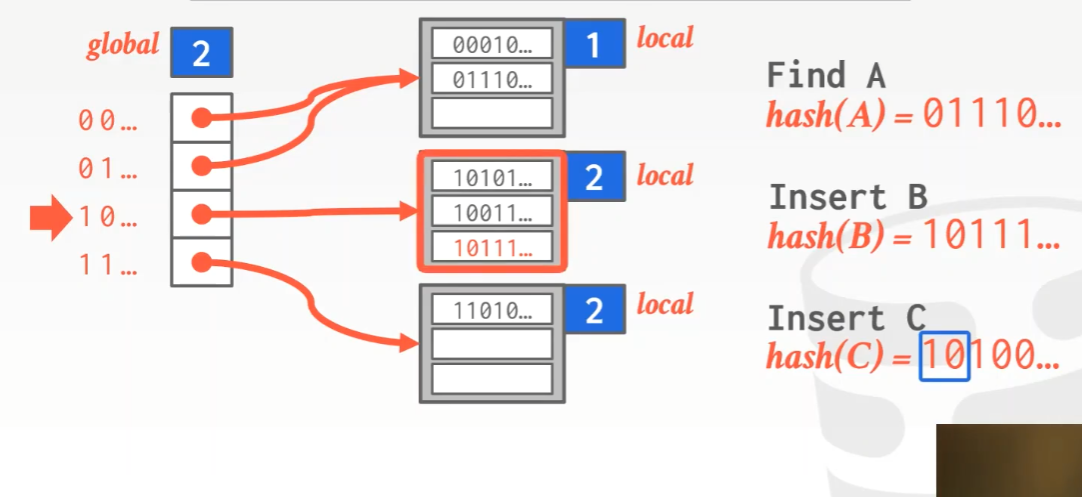
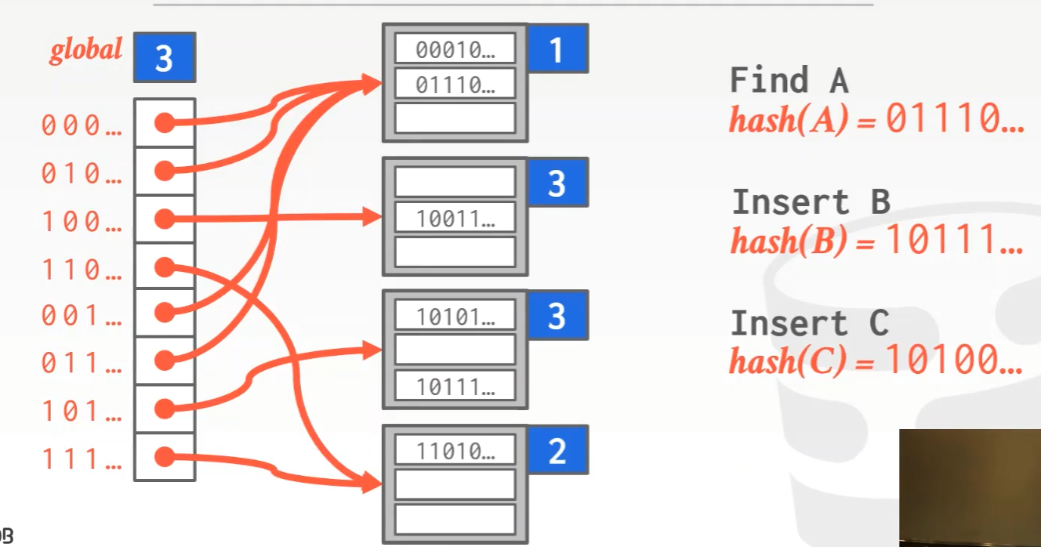
3) Linear Hashing
Extendible Hashing每一次扩容都会变成原来的两倍大小(每多考虑一个bit,相当于乘以2),此时hash table需要加锁导致不能被其它线程访问,这会导致性能的瓶颈,因此Linear Hashing提出了一种方法,其只需要去分配那些溢出的bucket(这样扩容的量就少了?)。其有一个split pointer指向hash table中的链表头,如果有一个bucket有溢出的现象,DBMS就在hash table的末尾加上一个新的链表指向一个新的bucket,将split pointer指向的bucket的slots一分为二到新的bucket中,之后添加一个新的hash function(如果原来的hash function为key%n,现在就是key%2n),同时split pointer下移。split pointer用于指示我们应该使用哪种hash funciton,当我们查找一个slot时,如果使用第一个hash function的结果在split pointer上方分割线的上面的bucket中,那么就表明该查找的slot所在的bucket被拆分了,这时就可以视情况使用第二个hash function了。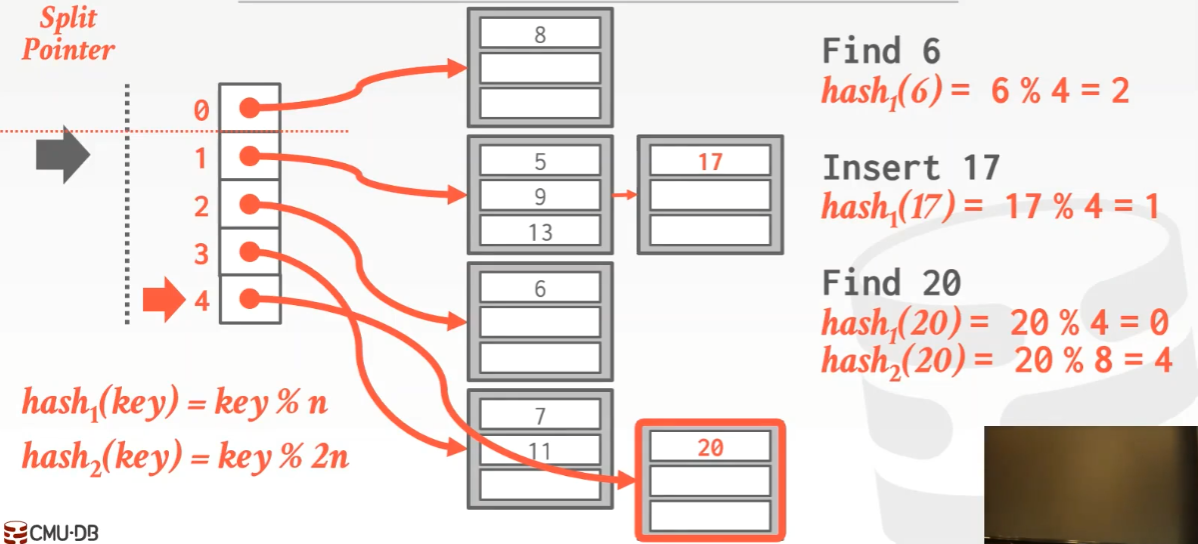
- 本文标题:CMU15-445笔记5——Hash Table
- 本文作者:mufiye
- 创建时间:2022-08-22 16:30:48
- 本文链接:http://mufiye.github.io/2022/08/22/CMU15-445笔记5——Hash-Table/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!