
1. Buffer Pool Manager
1.1 Buffer Pool Organization
我们为buffer pool分配一块大的内存,并将我们从磁盘中读取到的所有page放入里面。这段内存是由数据库系统来控制的,而不是操作系统。我们将buffer pool分为一个个frame来存放page。当执行引擎请求数据时,如果在buffer pool中找不到对应的数据,DBMS会从磁盘上取出相应的page存放到buffer pool中的frame中,page在frame中存放的顺序并不是按照其在磁盘上的顺序,因此我们需要一个indirection层来寻找相应的page。
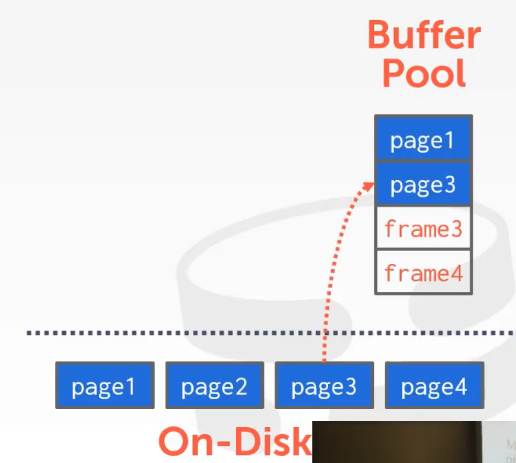
1.1.1 Buffer Pool meta-data
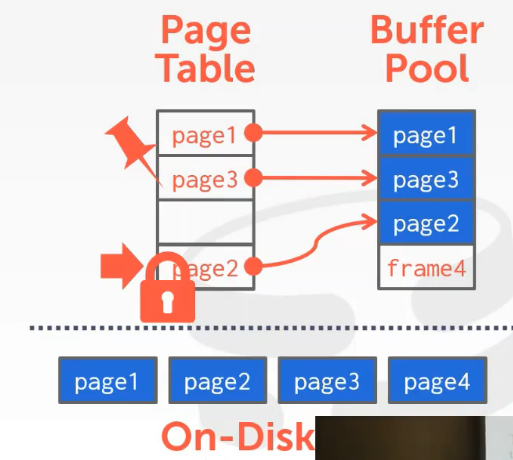
1.1.2 Locks vs. Latches
Locks
- 用来保护数据库中的逻辑内容,例如:tuple,表和数据库
- 事务会在运行的时候持有这个lock
- 需要支持回滚(rollback)
Latches
- 用来保护DBMS的关键部分,例如保护数据结构和保护内存区域
- 执行操作的时候会持有该latch,执行完该操作后释放
- 无需考虑回滚,因为latch是一个内部的东西
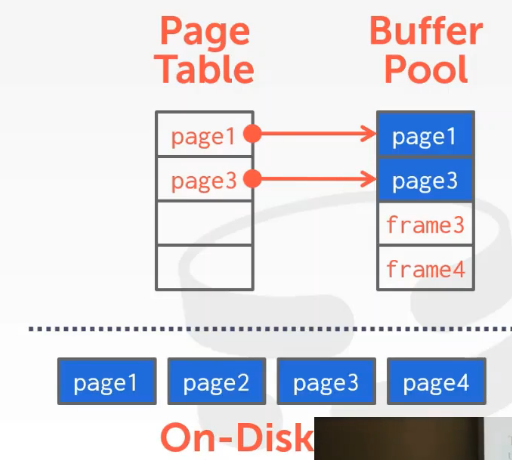
1.1.3 Page Table vs. Page Directory
- Page Table
- page table保存的是page id到buffer pool中frame的映射
- 不需要持久化
- Page Directory
- page directory保存的是page id到数据库文件中page位置的映射
- 需要持久化在磁盘中
1.2 Allocation Policies
Allocation Policies是指如何为数据库中的buffer pool分配内存。
1.2.1 Global Policies
全局策略,这种策略能够使所有要执行的workload都受益。
1.2.2 Local Policies
局部策略,针对每个单个查询或者单个事务来进行。
1.3 Buffer Pool Optimizations
1.3.1 Multiple Buffer Pools
DBMS可以有多个buffer pool,每个buffer pool都有自己的page table。我们可以一种数据库对应一个buffer pool,也可以一个数据表对应一个buffer pool。
优点:
- 这样可以在每个buffer pool使用不同的策略。
- 这样做可以减少那些试图访问buffer pool的不同线程争抢latch的情况发生。
两种方式实现multiple buffer pools(如何将你要寻找的数据映射到某个buffer pool中的某个page上):
1)Object Id
将object id嵌入到record id,之后维护一个object到特定buffer pool的映射。
2)Hashing
将page id做hash操作来选择access哪个buffer pool。
1.3.2 Pre-Fetching
根据请求计划预取数据来减少停顿(将磁盘中的数据读取到内存中会产生停顿)。DBMS相比于操作系统知道更多查询的细节,其预取page能够做更好的优化。
1.3.3 Scan Sharing
扫描共享,有一些请求的数据(page)可以重用。这与result caching不同,result caching是重用相同的查询的结果。扫描共享将一个查询的游标附着在另一个做相似查询的游标上,并且记录已经扫描的buffer pool的位置,这样就可以避免重复的扫描。(关于buffer pool中的page会被移除和回写的问题,不用担心,pin counter会对其进行阻止。)
1.3.4 Buffer Pool Bypass
我们分配一小块内存给执行查询的那条线程,之后该线程读取某数据时,如果该数据不在buffer pool中,那么从磁盘中拿到该page后将其放入到本地内存中(而非buffer pool中),当查询执行完后,这些内存中的page被丢弃。
优点:
- 减少了很大一部分的开销(page table的查询开销,以及latch)
- 很适合读取在磁盘上连续存储的页
- 可以被用于一些临时的数据(中间结果),比如sorting,joins
缺点:
- 数据量过大的时候不适合使用
1.4 OS page cache
操作系统读写文件时会有缓存,大多数DBMS会使用direct IO来避免产生操作系统的缓存。目前来看,使用操作系统缓存的DBMS只有Postgres。
如果使用操作系统缓存,那么就相当于两份page,一份在buffer pool中,一份在操作系统的缓存中,这会导致冗余。当buffer pool中的page被修改了,缓存中的page就毫无用处了。
保证跨操作系统的管理一致性。
2. Replacement Policies
Buffer Pool替换策略是指决定buffer pool中的哪个frame被换出以此为换入的page提供空间。
Goals:
- 正确性:如果某个数据我们并没有真正地使用完,那么我们不想将它写出或移除。
- 准确性:希望能够确保所移除的page是在未来不太会被使用到的那些page。
- 速度:希望该策略的执行是较为快速的。
- 元数据的开销:希望元数据的开销尽可能的小。
2.1 Least Recently Used
Least recently used策略是指最近最少使用策略,该策略记录page的时间戳(每次access会更新时间戳),优先替换时间戳最老的page。
2.2 Clock
Clock是一种类似于LRU的策略,该策略无须去追踪每个单个page的时间戳,而需要去追踪每个page的标志位(reference bit),这个标志位指示的是这个page是否被访问了。将page组织成一个环形的buffer,然后有一个能够旋转的指针去检查每个page的该标志位是1还是0,如果其为0,那么就表示自从上次被检查后,该page没有在被访问了,因此将该page从这个环形buffer中移除,如果其为1,我们将其设置为0,并访问下一个page的该标志位。
Sequential Flooding
LRU与Clock策略都会受到sequential flooding的影响,如果一个查询是顺序地读取每个page,那么这个查询会导致buffer pool被只使用一次的page所污染,而真正之后需要的page被移除了。
2.3 LRU-K
被访问了k次的page会被记入缓存队列,同时根据时间戳计算出某个page多久没被使用来决定哪个page被移除。
2.4 Localization
使用多个buffer pool,使每个查询之间相互独立,每个查询的缓存page存入到对应查询的buffer pool中。例如Postgres就为查询维护了一个私有的、小的环形buffer pool。
2.5 Priority Hints
DBMS在查询执行时能够知道每个page的上下文信息,因此其能够提供给buffer pool某些page的重要性。
2.6 Dirty Pages
每个page有一个dirty bit来指示该page在被读入buffer pool后是否被修改,而在替换page时需要考虑这一点,有两种关于dirty page的替换策略:
- FAST:如果buffer pool中的页不脏,DBMS直接移除它。
- SLOW:如果buffer pool中的页是脏的,DBMS必须首先将内存中的page写回到磁盘中,之后在移除它。
在具体的替换策略中,需要在替换最近可能被使用+非脏页和最近不会被使用+脏页中进行权衡。
Background Writing
后台写操作,DBMS中有一条执行定时任务的线程,它会去buffer pool中找出那些被标记为dirty的page并将它们写出到磁盘上,以此将page的状态由dirty变为clean。要注意在回写前首先写操作日志到磁盘上。
3. Other Memory Pools
除了用于tuple和indexes的内存空间,DBMS需要其它的内存池。
- Sorting+Join Buffer
- Query Caches
- Maintenance Buffers
- Log Buffers
- Dictionary Caches
- 本文标题:CMU15-445笔记4——Buffer Pools
- 本文作者:mufiye
- 创建时间:2022-06-20 10:49:12
- 本文链接:http://mufiye.github.io/2022/06/20/CMU15-445笔记4——Buffer-Pools/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!