MIT6.824笔记1——Introduction

Introduction
分布式系统的特点:
parallelism
fault tolerance
physical
security / isolated
分布式系统面临的挑战:
- concurrency
- partial failure
- performance
分布式系统在基础架构的使用:
- Storage
- Communication
- Computation
分布式系统的实现工具:
- RPC
- threads
- concurrency lock
分布式系统需要考虑的:
- Scalability:两倍的计算机数量能让我获得两倍的性能
- Availability:发生故障时的可用能力
- Recoverability:从故障中恢复的能力,依靠非易失性存储和副本
- consistency:一致性,考虑它的原因是,在分布式系统中,经常有不只一份数据
- 强一致性:很耗时
- 弱一致性
MapReduce
1. Overview
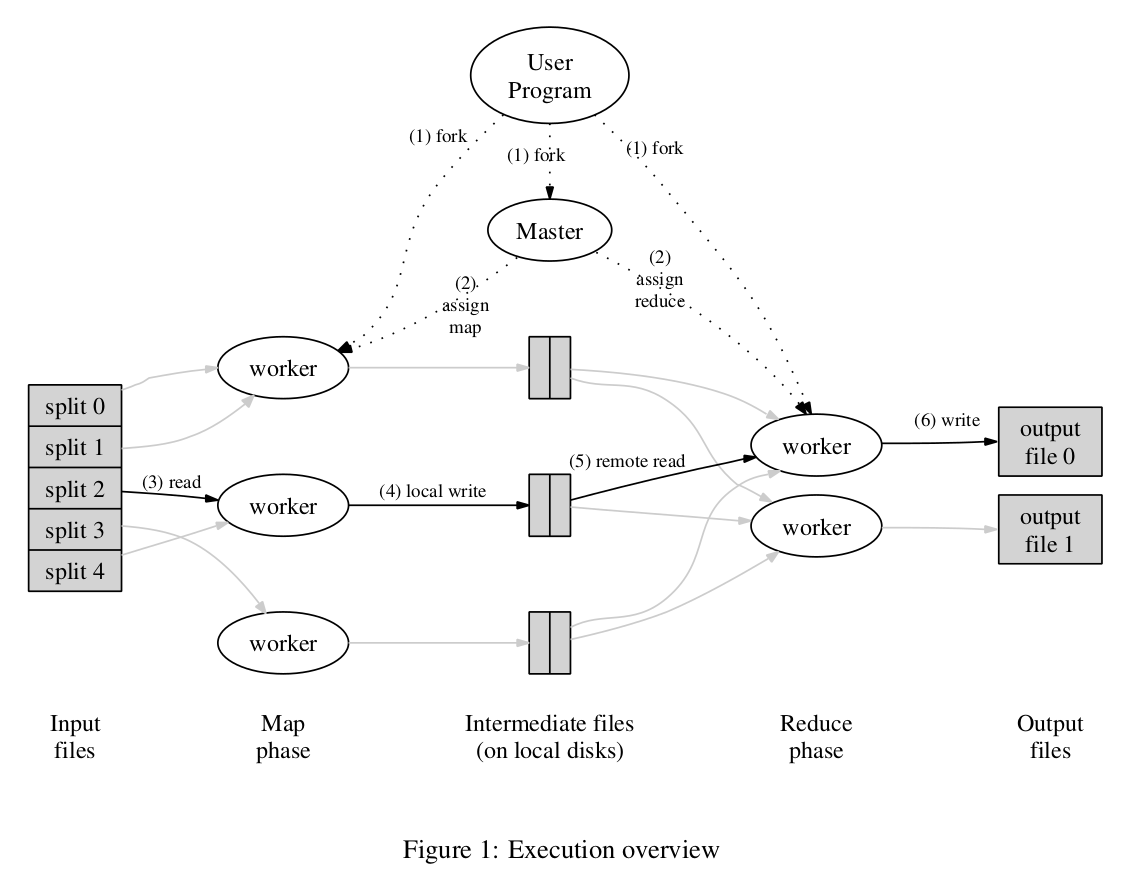
MapReduce是一个分布式的框架,其主体处理部分为map function和reduce function。其一整个处理流程为一个job,它是由一系列的map task和reduce task组成的。在该架构中,master负责任务的调度,worker负责map和reduce任务的执行。
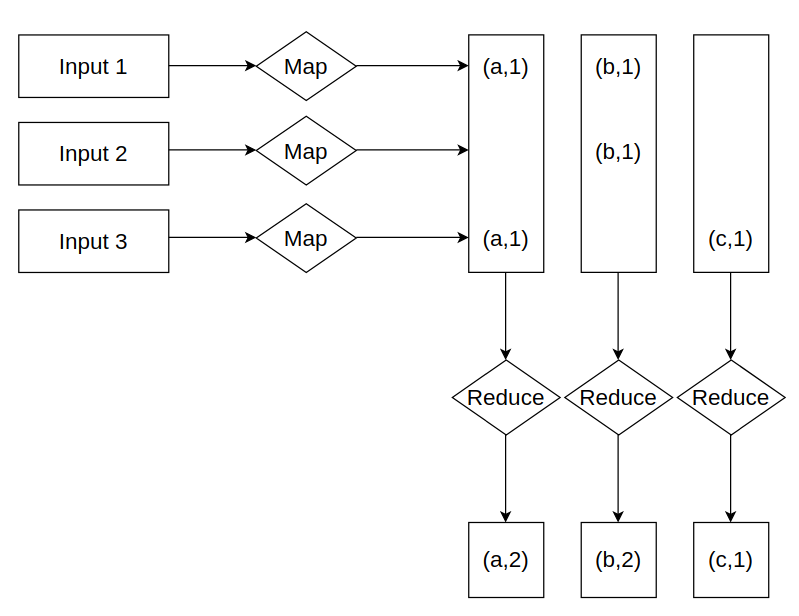
我们可以通过一个统计文档中词频的任务来理解MapReduce这个框架,处理的流程如下图所示,输入的Input是一个文档,我们假设在第一个文档中统计到词语a出现了1次,词语b出现了1次,第二个文档中词语b出现了1次,第三个文档中词语a出现了1次,词语c出现了1次。Map function处理后也就得到了中间结果key/value键值对,之后Reduce function根据key的种类进行操作,最后分别得到不同词语的出现总次数。
下面的代码块表示的是词频统计任务中的Map function和Reduce function。
1 | /* Map函数的k是文件名;v是输入文件的内容。*/ |
1 | /* Reduce函数的k是单词;v是一个vector,统计的词数,在最简单的例子中,元素值都为1 */ |
MapReduce中间结果的存储(Map函数的处理结果)先存储到本地,之后被Reduce function读取(涉及网络传输)。但是MapReduce的输入和输出文件的存储依赖于GFS这个文件系统(google三驾马车之一)。
- 本文标题:MIT6.824笔记1——Introduction
- 本文作者:mufiye
- 创建时间:2022-06-03 12:47:00
- 本文链接:http://mufiye.github.io/2022/06/03/MIT6-824笔记1——Introduction/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
评论