
1. 数据库系统设计
数据库系统设计目标:给应用程序一个错觉,即我们能提供足够的内存将整个数据库存入内存中。
1.1 整体的设计架构:
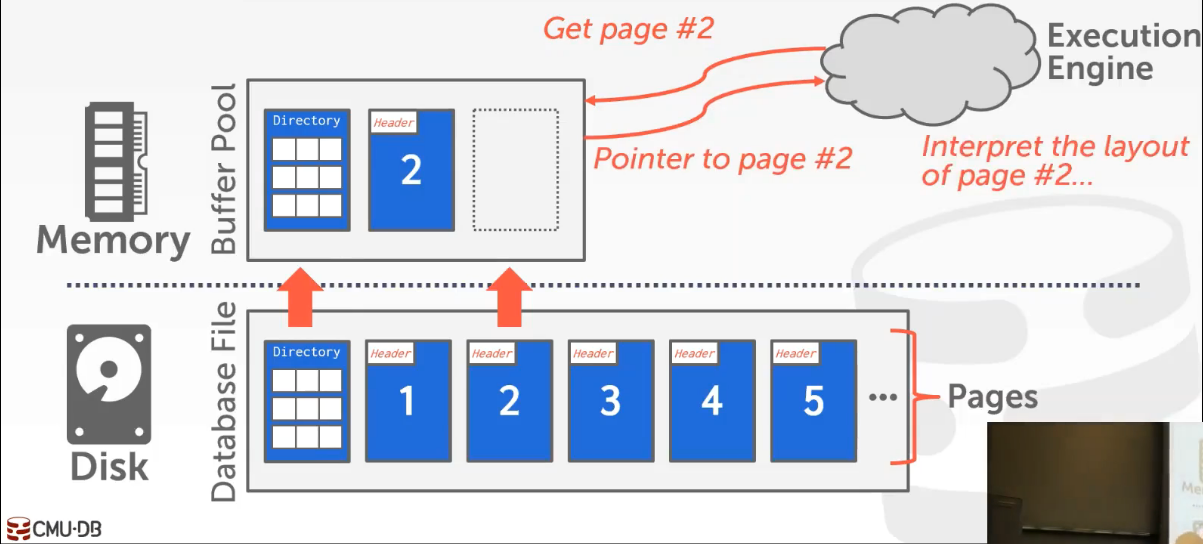
在硬盘中有数据库文件,其由目录和页(也可以说是块)组成;在内存中有一个缓存池,用来缓存数据库文件中的页。当一个运行引擎(查询引擎、执行引擎等)需要得到page 2中的内容,它会向缓冲池发送请求,如果page 2不在缓存池(内存)中,其会在硬盘的page目录中查找page,并将其读取到缓存池中,最后将数据交给运行引擎,运行引擎会对读取到的数据进行相应的操作。
1.2 Why Buffer Pool
为什么不依赖操作系统去管理内存,而要额外写一个buffer pool去管理内存呢?用户程序可以使用mmap系统调用让操作系统将文件页面映射到进程的地址空间中,其可以读写该内存页中的内容,操作系统会控制该内存内容,将更改内容写回到硬盘文件中。通过这种方式,操作系统控制了硬盘文件数据在内存中的缓存。
但这会导致一些性能瓶颈,因为操作系统只是从操作系统的层面去考虑控制文件数据在内存中的缓存(如果内存满了,需要换出换入页,那么极有可能换出从DBMS层面来看不该换出的页)。虽然DBMS可以使用madvise告诉操作系统如何访问某些页面(顺序读取还是随即读取),可以使用mlock阻止pages被回收,可以使用msync告诉操作系统要将数据刷出到磁盘中。但是这样仍然可能会遇到性能瓶颈。所以我们要尽可能避免使用操作系统来管理这部分内存,而将这部分工作交给DBMS。
从发展现状来看,大多数主流的数据库比如MySQL、Oracle、DB2以及SQL server都没有使用mmap。当然也有一部分数据库使用了或者部分使用了mmap,前者有levelDB、elasticsearch,后者有SQLite、mongoDB。
2. 数据库存储——Problem 1
数据库存储主要关注两个问题,问题1是DBMS如何表示磁盘中文件的数据。
2.1 File Storage
数据库可能将数据存储在一个或多个文件中,其所依赖的文件系统有可能是基于操作系统自带的一些文件系统或者是自己构建的。
2.1.1 Storage Manager(存储管理器,存储引擎)
数据库系统的一个组件,负责维护在磁盘上的数据库文件。
2.1.2 Database Pages
- page里面的内容可以是元组、元数据、索引或者日志,分开存储不同类型的数据是一个好的方法(大多数系统都是这样做的,称为self-contained page)。
- 每一个page都有一个独一无二的id号,利用id号可以索引到该页的物理位置(使用一个indirection layer)。
三种不同的page概念:
- Hardware Page(usually 4KB):存储在持久化设备上的数据块(执行原子性读写的最小单位)
- OS Page(usually 4KB):被操作系统读取,存在内存中的数据页
- Database Page(512B - 16KB):DBMS处理的page,如果Database Page的大小大于Hardware Page的大小不一样,在读写发生异常时可能会出现问题,比如16KB的Database Page刚写了8KB到持久化设备中,这时设备宕机了,那么剩下的8KB还没有写完,而当读取数据库数据时,实际上已经有一部分数据被修改了,这就需要一些操作来保证数据一致性。而使用更大的Database Page的好处是更大的页大小可以使索引表中(类似TLB)的page id数更少(在总数据量相同的情况下),这可以使读取page位置的操作更加快速。
2.1.3 Page Storage Architecture
不同的DBMS使用不同的方式管理数据库文件中的页。关注的是页的组织形式,而不是页中的内容。
1)Heap File Organization
heap file是一个无序的page集合,可以以随机的顺序把tuple保存在里面。(关系模型没有任何排序,如果一个接一个地插入tuple,不能保证它们是按照插入的顺序保存在磁盘上的。)这种架构还需要元数据去跟踪记录被使用的page和空闲的page。
heap file有两种实现方法:
实现方式1: Linked List(bad idea)
在heap file的header中,用两个指针来分别指向空余page列表和被数据占据的page列表。当我想要插入数据时,我可以循环扫描查看每一个page,知道找到有足够空余空间的page为止。
实现方式2: Page Directory
在heap file的header有一个目录维护了page id和它们所处位置的映射关系,同时这个目录维护着某些额外的元数据。
2)Sequential/Sorted File Organization
没讲
3)Hashing File Organization
没讲
2.2 Page Layout
page layout是指如何组织储存在page中的数据。
2.2.1 Page Header
- Page Size
- Checksum
- DBMS version
- Transaction Visibility
- Compression Information
2.2.2 Tuple-oriented
1)a strawman idea
在一个已有的tuple后面再接着插入一个新的tuple,同时更新header中记录的page中tuple的数量。
缺点:删除后很容易产生外部碎片,同时维护header中的数据过于频繁。
2)Slotted Pages
这是常用的scheme。使用该方法存储数据,在头部除了存储元数据还要存储slot array,在尾部存储我们想要保存的tuple。Slot array将一个特定的slot映射到page上的某个偏移量上,根据这个偏移量,DBMS可以得到想要获取的那个tuple。(也有可能会产生空隙,DBMS可以压缩page中的空间。)
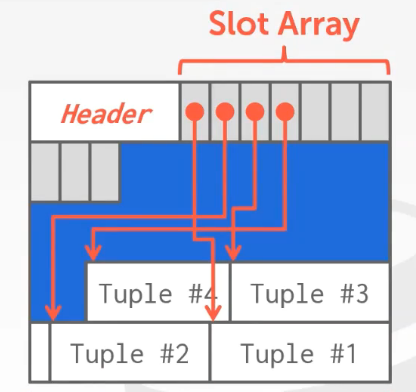
每一个tuple可以用一个record id来唯一标识,最常用的record id为page id + slot offset。
2.2.3 Log-structured
该方法并不是把所有的tuple都存放到page中,而是去存储如何创建tuple以及如何修改tuple的相关信息(也就是日志记录)。(这其实和LFS这个文件系统思路一致。)
优点:
- 考虑了存储介质上顺序读写与随机读写的区别(这种结构有利于顺序读写)
- 有利于回滚
缺点:当读取数据时需要读取一堆记录来得到数据。
2.3 Tuple Layout
tuple其实就是一个字节序列。
2.3.1 Tuple Header
每个tuple前面都有一个包含元数据的header,我们可以通过一个header来追踪一些不同的东西,例如哪一个事务查询修改了这个tuple,以及对于空值的bitmap。但是通常我们不会将数据类型元数据保存在每个tuple中,而是会保存在tuple所在的page中,或者是另外的catalog page中(假设同一个表的tuple会在同一个page中)。
2.3.2 Tuple Data
关于tuple data的存储顺序,通常是根据创建表的时候类型的顺序来存储的。(对于内存型数据库,可能需要重新排序以此来保证字节对齐)
2.3.3 Denormalized Tuple Data
反范式化(范式化是尽可能地将一个表进行拆解,使其耦合性降低,反范式化是其反面)相关联的tuple,将它们存储在同一个page中。
- 潜在地减少常见工作负载模式的IO量(因为只需要读一个page了)
- 使更新数据变得昂贵的(数据量变大了)
3. 数据库存储——Problem 2
数据库存储关注的第二个问题是我们实际该如何管理内存以及在硬盘间来回移动数据。
我们主要考虑的是面向磁盘的架构设计,这种DBMS假设首要的存储位置是在非易失性存储上。DBMS的组件管理着数据从非易失性存储(磁盘)移动到易失性存储(内存)上。
3.1 Data Representation
3.1.1 Storage of different data type

- variable-precision number(IEEE-754标准):处理速度更快,但是有取舍的误差。
- fixed point decimal number:固定精度数字,利用元数据来存储确切的二进制表示(哪里是小数点,哪里是精度范围,哪里是四舍五入信息)。
3.1.2 Store Large Values
1)Overflow Page
如何存储size比一页要大的值。DBMS可以使用额外的overflow page来存储这些页。如果一个tuple中有一个size比page size要大的值,该值会放在overflow page中,而该tuple中在该值的位置会存放一个指向overflow page中该值的指针(overflow page的page id + slot id)。
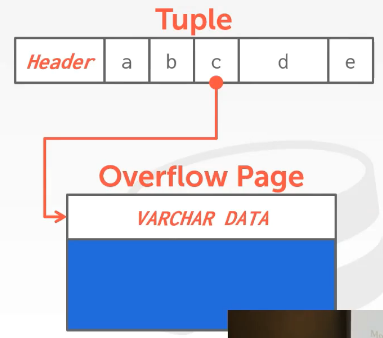
如果该overflow page也无法存放该值,其会类似地将该值存放到其它page中,该overflow page存放指向那个位置的指针(和前面一样,也是个record id)。
2)External value storage
还有另一种方法,就是将大数据存放到外部文件中,而在tuple中的对应位置保存一个指针或者是一个文件路径指向能找到该数据的本地磁盘、网络存储或者是外部存储设备。但是DBMS没有办法修改外部文件的数据,没有一致性保护和事务保护。(可以用该方法存放视频文件等大数据,考虑性能和经济效益。)
3.2 System Catalogs
DBMS在目录中存放了关于数据库的元数据。很多DBMS都会将它们的catalog用另一张表来保存。在SQL标准中,使用INFORMATION_SCHEMA来访问该元数据。
- 表名,索引,视图
- 用户以及其权限
- 内部统计数据
1 | # PostgreSQL |
3.3 Storage Models
3.3.1 Workload
1)OLTP
OLTP是指On-line Transaction Processing,联机事务处理。联机事务处理是指读/更新一小部分关联到数据库中条目的数据。
2)OLAP
OLAP是指On-line Analytical Processing,联机分析处理。联机分析处理是指从收集到一大堆数据后,分析它们并且推断出新的信息。
3)HTAP
HTAP是指hyper transaction analytical processing混合事务分析处理,它混合了OLTP和OLAP。
Q: SQL, NoSQL, newSQL
3.3.2 N-Ary Storage Model(NSM)
行存储,其基本思路是将单个tuple中的所有属性取出,并将它们连续地存储在我们的page中,这样我们取数据就可以以一行为粒度连续地读取。这种存储方式比较适用于OLTP这种workload,因为其通常只需要读/更新一小部分数据(这些数据在行存储的page中通常是连续的)。
优点:当我们访问整个tuple时,插入、更新以及删除数据时的速度很快。(针对的是想要获取单个或者多个tuple的全部属性)
缺点:做OLAP工作的性能很糟糕,因为这通常需要去扫描整张表中的大部分内容。
3.3.3 Decomposition Storage Model(DSM)
列存储,将单个列(单种属性)所有值连续地保存在一起。每个page对应于一种属性。列存储的数据可以进行压缩,以此让一个page可以存储更多的数据?
优点:适合做OLAP,相较于行存储其做OLAP无效的IO做得更少。更有利于查询处理和数据压缩。
缺点:对于查询、插入、更新和删除一个tuple的操作,处理速度很慢。
1)Tuple Identification
如何从一个page中找到一个匹配项。
Fixed-length Offsets
使用固定长度的偏移值。对于一列中的每个值来说,它们的长度始终是固定的(利用填充或者压缩属性值使其长度为统一长度)。offset * value size得到匹配项的位置。
Embedded Tuple Ids(废弃)
每一个值与其tuple id一起存储,我们通过一个map来查找这个匹配项。
3.3.4 Bifurcated Environment
- OLTP Data Silos(数据孤岛)
- OLAP Data Warehouse(数据仓库)
1)OLTP + OLAP
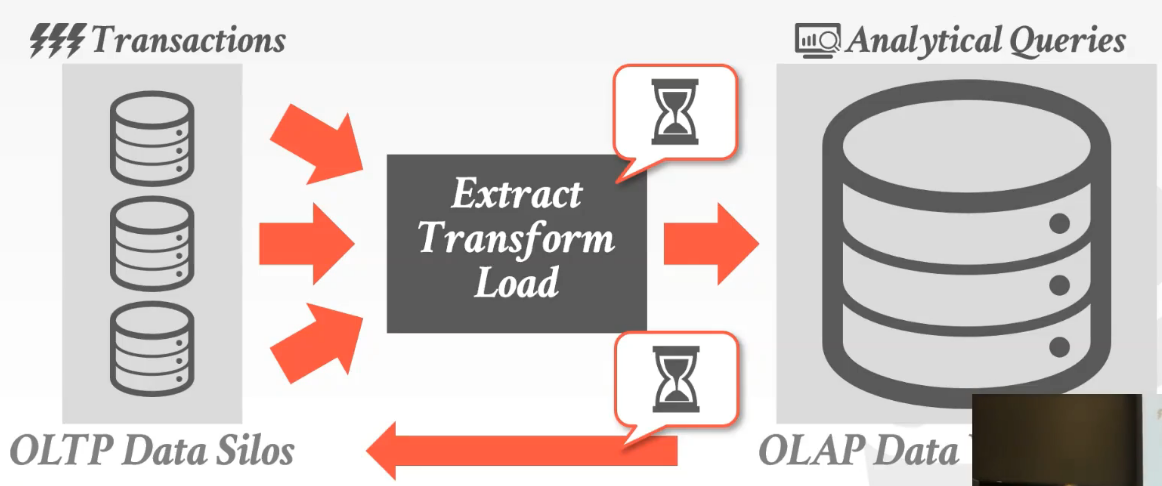
在每个数据孤岛上做OLTP,然后就可以进行被称为ETL的操作,该操作是指从前端数据库中取出数据,将数据进行清洗处理,接着将处理后的数据传入到后端的数据仓库。之后在后端的数据仓库进行OLAP,后端数据仓库可以将分析得到的结果存入到前端的数据孤岛上。
2)HTAP
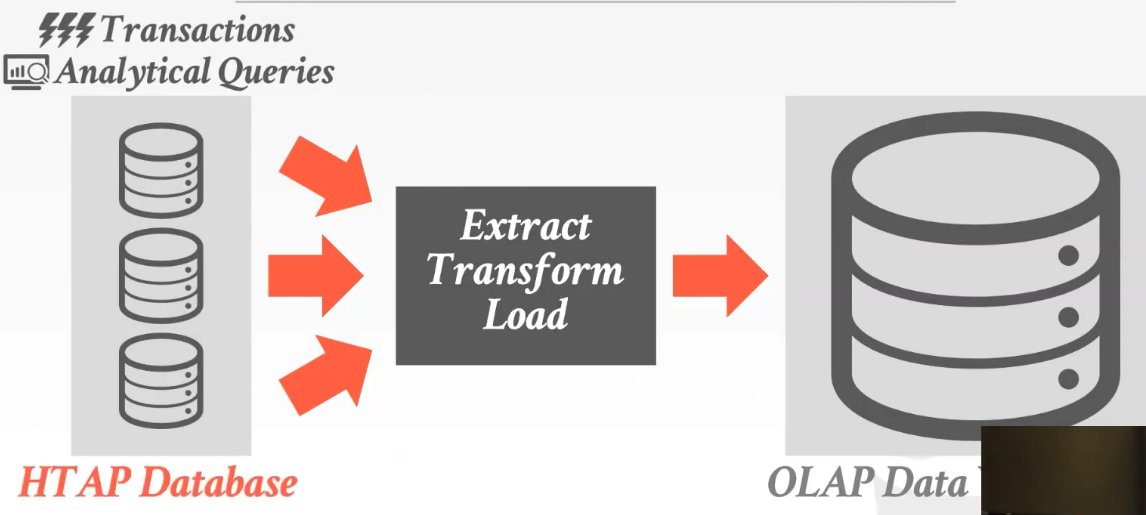
HATP在前端的数据孤岛上既做OLTP,也做OLAP。
3.3.5 Conclusion
对症下药,混合是一个bad idea。
OLTP = Row Store
OLAP = Column Store
3.4 Some Think
想要最小化在磁盘上执行查询速度缓慢带来的影响。
3.4.1 Spatial Control
Spatial Control是指我们实际将数据写入到了磁盘的哪里,我们应当尽可能地使要一起用的page在磁盘上的物理位置接近。
3.4.2 Temporal Control
Temporal Control是指什么时候将数据读到内存之中,并且如果它们被修改了,我们什么时候将其回写到磁盘之中。其目标是减少我们必须要从磁盘中读取数据的次数。
- 本文标题:CMU15-445笔记3——Database Storage
- 本文作者:mufiye
- 创建时间:2022-06-02 19:35:54
- 本文链接:http://mufiye.github.io/2022/06/02/CMU15-445笔记3——Database-Storage/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!